How to Stop Recurring Downtime by Managing Daily Operations?
January 6, 2026
Recurring downtime is rarely a reliability problem. It is almost always a design flaw in how daily operations manage equipment between failures.
Many plants with strong maintenance programs still experience:
- The same machines breaking down repeatedly
- Downtime clustering around startups, shift changes, or high-mix periods
- MTBF that refuses to move despite good technicians and PM compliance
This creates a false narrative: “Maintenance needs to be done better.”
In reality, maintenance may be performing exactly as designed.
What’s failing is the operational logic that governs how equipment is run after it is repaired. When downtime recurs, the plant hasn’t failed to fix the machine — it has rebuilt the conditions that allow failure to return.
Why Maintenance Gets Blamed for an Operational Design Failure ?
Maintenance is visible because it restores the asset at the moment of failure. So when downtime returns, blame naturally points there.
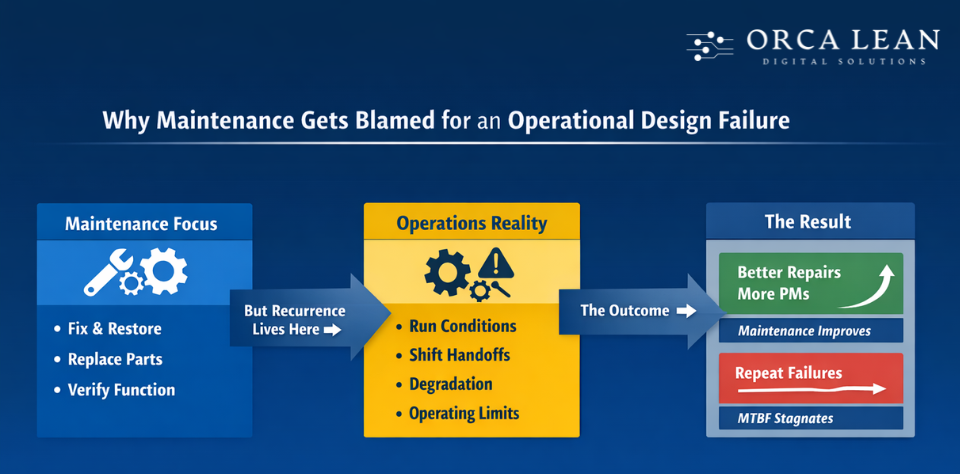
But recurrence is rarely created during repair. It is created after restart, during daily operation. Maintenance restores function:
- Parts replaced
- Asset returned to service
- Integrity verified
Operations controls what happens next:
- How the machine is run after restart
- How risk transfers across shifts
- Whether early degradation is acted on
- How operating limits slowly drift
When ownership ends at “maintenance fixed it,” repairs improve—but MTBF does not. Recurring downtime is not an execution failure. It’s an ownership gap in daily operations logic.
Result:
- Maintenance performance improves.
- MTBF does not.
The problem isn’t execution. It’s where ownership ends.
Where Downtime Actually Recurs: The Space Between Failures?
Most plants manage downtime at two moments:
- When the machine fails
- When the machine is fixed
What remains unmanaged is the entire operating window in between — the space where recurrence is born.

In that space:
- Operating conditions slowly drift
- Temporary adjustments become permanent habits
- Minor abnormalities are tolerated because “the line is running”
- Risk accumulates silently
Downtime does not repeat because the repair failed. It repeats because nothing governed how the asset lived afterward.
This is why MTBF feels uncontrollable. It isn’t actively managed — it’s passively measured.
The Silent MTBF Killer: Cross-Shift Ownership Collapse
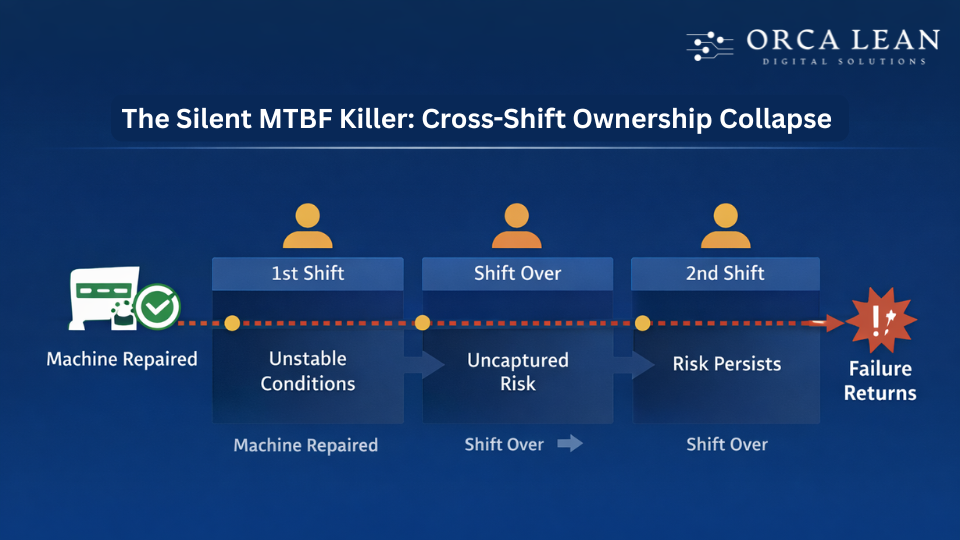
Cross-shift ownership collapse is rarely intentional. It happens because risk has no formal carrier once the line is running.
After restart, the priority shifts to making plans. Small abnormalities are noticed, but tolerated. Nothing looks urgent enough to stop the line.
When shifts change:
- Information stays verbal or incomplete
- Temporary conditions are not owned
- Risk resets instead of transferring
Time passes. The risk remains.
When the failure finally occurs, it appears sudden — but it isn’t.
The machine didn’t degrade rapidly. The organization allowed risk to travel unchecked across time. That’s why MTBF shrinks and downtime clusters around shift changes and startups.
Why Weekly Downtime Reviews Cannot Stop Daily Recurrence?
Weekly downtime reviews are excellent for reporting. They are structurally incapable of preventing recurrence.
By the time downtime is reviewed:
- The same operating conditions already exist again
- Operators have adapted around instability
- The failure path is already rebuilding itself
Downtime recurrence operates on a daily cycle. Weekly governance reacts too late. This is why plants with strong review discipline still experience:
- Flat MTBF
- Volatile downtime %
- Repeat failures with “known causes”
Understanding downtime is not the same as controlling it.
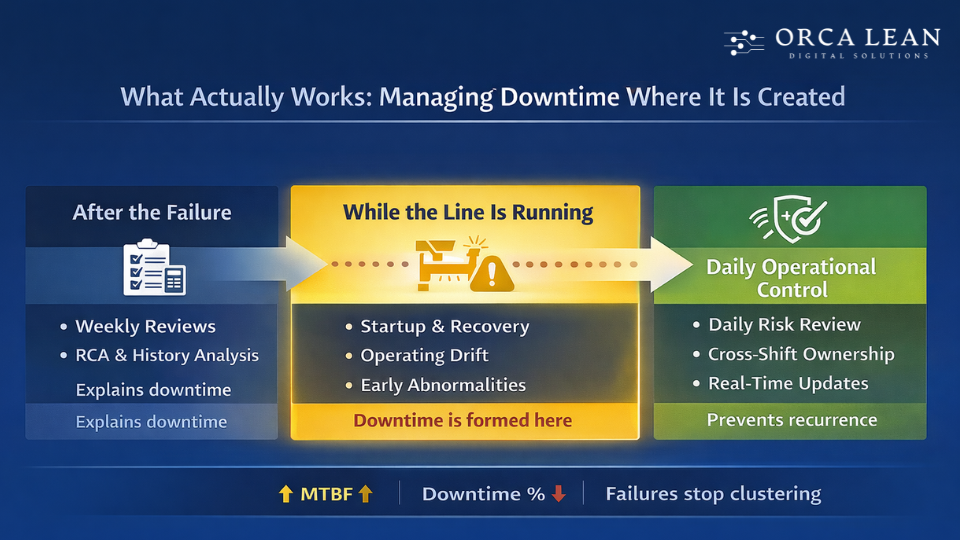
What Actually Works: Managing Downtime Where It Is Created
If weekly downtime reviews cannot stop daily recurrence, the answer isn’t more analysis — it’s changing where control is applied.
Downtime does not originate in reports or meetings. It is created on the shop floor, during daily operating decisions made while the line is running.
What works is shifting control upstream — into the moments where risk first appears.
Effective plants focus on:
- Managing degradation, not just failures
- Owning risk between breakdowns, not just during repairs
- Acting while conditions are unstable, not after downtime occurs
This requires moving from retrospective thinking to real-time operational control.
Instead of asking:
“Why did this machine fail?”
High-performing operations ask:
“What conditions exist today that could cause the next failure — and who owns them now?”
When downtime is managed at the point of creation — during startup, recovery, and steady-state running — MTBF improves naturally and downtime stops recurring.
This is not a maintenance upgrade. It is an operating model shift.
Also Read: The Fast-Track to Problem-Solving: How Cross-Functional Teams Reduce Manufacturing Downtime
The Solution: Daily Operations Logic That Stops Downtime from Returning
Elite plants do not “fight downtime.”
They design daily operations logic that prevents failure conditions from reforming.
That logic is difficult to sustain with whiteboards, spreadsheets, and verbal handovers. High-performing plants support it with a single operational system that makes risk visible, owned, and actionable every day. This logic rests on three operational mechanisms.

1. Daily Review Cycles Focused on Asset Behavior — Not Just Failures
Daily reviews answer different questions than weekly meetings:
- What degraded yesterday even though we ran?
- Which assets are operating outside normal conditions?
- What risk must be stabilized before the next shift?
In mature plants, these questions are reviewed daily using live operational data, not recollection.
Manufacturing KPI Tools like FactoryKPI structure these conversations by:
- Surfacing asset behavior trends, not just downtime events
- Highlighting instability while the line is still running
- Making “ran but degraded” visible instead of invisible
This keeps recurrence from rebuilding quietly.
KPI impact:
- MTBF ↑ by preventing early-life failures
- Downtime % ↓ through proactive stabilization
2. Explicit Cross-Shift Ownership Transfer
Risk must move cleanly across time. High-performing plants:
- Transfer unresolved equipment risks explicitly
- Assign ownership that survives shift boundaries
- Ensure temporary conditions do not “reset” at handover
This breaks down when handovers rely on memory or verbal updates.
With a shared operational view:
- Risk stays attached to the asset, not the shift
- Ownership is visible across teams
- Open conditions follow the clock, not the people
Ownership follows the risk, not the shift schedule.
KPI impact:
- Downtime % ↓
- MTBF ↑ through continuity
3. Real-Time Updates While the Line Is Running
Recurrence is prevented when abnormalities are addressed before failure.
This requires:
- Real-time visibility into emerging issues
- Clear escalation logic for operations
- Decisions triggered during production — not after downtime
Plants that rely only on end-of-shift reporting act too late.
When real-time operational signals are visible:
- Abnormalities are captured as they appear
- Decisions are made while recovery is still possible
- Downtime is avoided rather than repaired
KPI impact:
- Downtime avoided
- MTBF extended without additional maintenance load
What Changes When Daily Operations Own Uptime?
When these mechanisms are embedded, plants typically see within 60–90 days:
- MTBF increase by 20–40%
- Downtime % reduce by 15–30%
- Fewer emergency maintenance calls
- More predictable schedules and output
Maintenance workload shifts from firefighting to improvement. Operations shift from reacting to controlling.
Conclusion — Downtime Stops Returning When Daily Operations Take Control
Recurring downtime is not a maintenance limitation. It is a signal that daily operations logic is incomplete.
When plants manage downtime only after it happens, failures keep returning. When they manage risk while the line is running, MTBF improves naturally and downtime stops clustering.
The shift is simple but decisive:
- From fixing failures → to controlling conditions
- From weekly explanation → to daily ownership
- From reacting to downtime → to preventing its return
This is where performance stabilizes — and stays stable.
If recurring downtime is still consuming capacity, labor, and margin in your plant, it’s worth seeing how daily operational control can be designed into the way your factory runs.
Book a demo to see how FactoryKPI enables daily reviews, cross-shift ownership, and real-time visibility — so downtime stops returning, not just getting repaired.
Software Solutions for Manufacturing Excellence
Company
Social
Our Contact Info:
Email: contact@orcalean.com
Phone Number: 248 938 0375
Our Offices